Machine Learning on Embedded System
What I want to do first
What I want to achieve for my final is using XIAO ESP32C3 as the mobile module, connecting with a INMP441 MicroPhone(week12), for changing my input audio frame into words(sentences) and then using Wi-Fi to send the words to my reComputer, finally outputing my calendar for me.
Here is the outline:
XIAO ESP32C3 audio frame receiver:
- Connect to the specified Wi-Fi network, local(192.168.66.xxx)
- Create a WiFiServer object and start listening on the specified port (80 in this case).
- In the main() function, check whether there is a client connection.
- If there is a client connection, read the data sent by the client until it encounters a newline ('\n'), and then print the received data to the serial port monitor.
And here is the code:
import network
import socket
ssid = 'your_wifi_ssid'
password = 'your_wifi_password'
port = 80
def connect_wifi():
sta_if = network.WLAN(network.STA_IF)
if not sta_if.isconnected():
print('Connecting to WiFi...')
sta_if.active(True)
sta_if.connect(ssid, password)
while not sta_if.isconnected():
pass
print('Connected, IP address:', sta_if.ifconfig()[0])
def start_server():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('', port))
server_socket.listen(1)
print(f'Server listening on port {port}')
return server_socket
def handle_client(client_socket):
while True:
data = client_socket.readline().decode().strip()
if not data:
break
print(data)
client_socket.close()
def main():
connect_wifi()
server_socket = start_server()
while True:
client_socket, addr = server_socket.accept()
print(f'Client connected from {addr}')
handle_client(client_socket)
if __name__ == '__main__':
main()
Here I have the ip address:
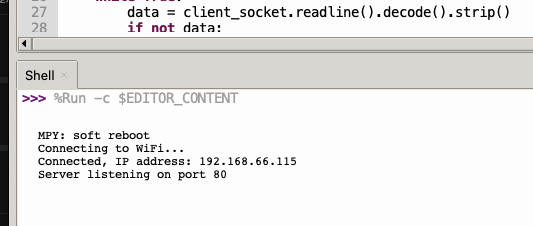
BUT
But I looked around that it appears that currently the MCU board can not convert the raw audio data into audio frames then output the sentences(too much for them). It requires Audio to Text Engine like Google and currenly the MCU board is not capable doing that.
There is another solution, by applying the data itself, which is the emabedded Machine Learning, on the embedded system(MCU board).
It can recoginze the words, for several ones, but it can do the work. Hence, in this part I am going to learning the embedded machine learning.
Knowledge about TinyML(embedded machine learning)
I got the machine learning knowledge from the Machine Learning Systems, published by Vijay Janapa Reddi, the professor in Harvard University.
Embedded machine learning is transforming how devices process data by integrating ML algorithms directly into hardware. This allows for real-time analysis without needing cloud connectivity. It first examines three main types of embedded ML: Cloud ML, Edge ML, and TinyML, each tailored for different scales and capabilities in smart sensors and microcontrollers.

(Quote from the book)
TinyML brings smart algorithms directly to tiny microcontrollers and sensors. These microcontrollers operate under severe resource constraints, particularly regarding memory, storage, and computational power.
The book brings different sections, including the workflow of AI, traning data, and the deployment. At the end, the professor shows the advanced topics: Responsible AI, Sustainable AI, Robust AI, Generative AI.
And this book presents all kinds of exerciese. What I am looking for is like this: "Audio Feature Engineering" or "Keyword Spotting (KWS)". They can use raw audio data, converting them into sample ones and outputing the words.
This is the principle for Audio Feature Engineering:
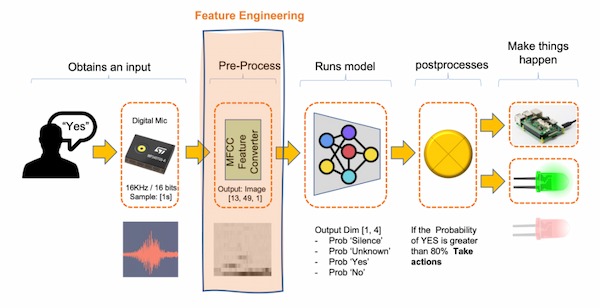
Actually, it does not use the raw data directly(16KHz sampling rate). Here is the reason. And it uses some feature extraction techniques like MFCCs, MFEs to generate features while reducing dimensionality and noise, facilitating more effective machine learning.
These are the MFCCs examples, for yes and no:

Here is one video explanning it.
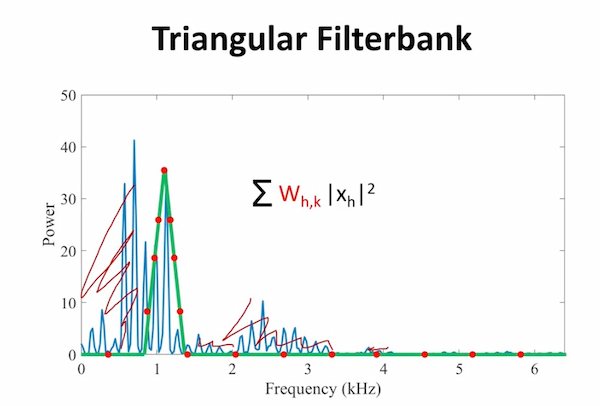
There are some steps requring to do so:
- Pre-emphasis
- Framing
- Windowing
- Fast Fourier Transform (FFT)
- Mel Filter Banks
- Discrete Cosine Transform (DCT)
Quite compliated, for the calculation. There actual are some tools I can directly use such as Edge Impulse, TensorFlow Lite. They simplified the steps and I can call the functions directly.
Words Recognization
Actually I have done this like two years ago, when I want to apply some simple controling. But at that time I am not familiar with the principle and the project is on hold as well - not very successful, I can carry on it now.
So the main idea is using voice to control this toy(voice recoginzation, motor control).

Capture Audio
I am using Seeed Studio XIAO nRF52840 Sense where there is aleady one microphone(Pulse Density Modulation) on it and I don't have to use my INMP441.

For tranning data, I need to capture the data. Here is the way to convert the data into wav files and this is the code:
WAV file is a file format used to store digital audio data.It not only contains audio data, but also some metadata such as sample rate, bit depth, number of channels, etc. It is good and needed for the word recognization.
For each time running the code there will be recording 5 seconds and writing to a WAV file. So it requires reset button to be pushed every time. It is using XIAO Expansion Board where there is an extra function of SD card.
The serial output is something like:
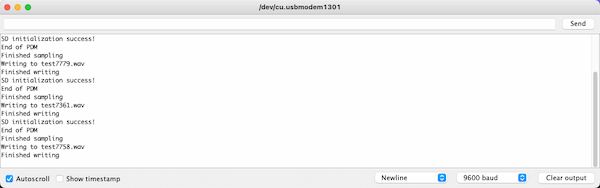
Then these are 40 senond audio file.
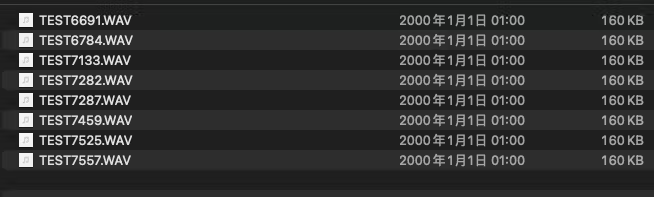
Tranning Audio(Edge Impulse)
Since I got the WAV audio files, I can upload them to the Edge Impulse.
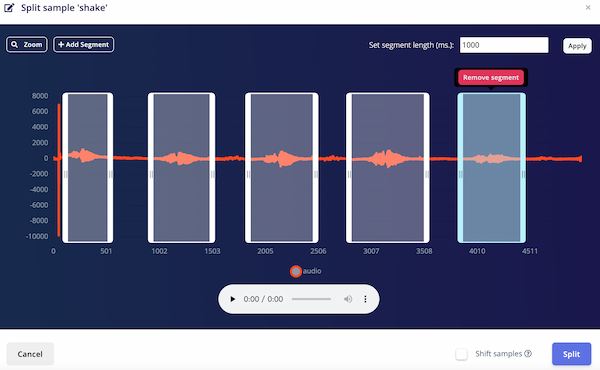
Because they are all 5 seconds and including multiple words of me, I should split them and make like 1 second.
Using the split Sample function to make sure one word one file:
After splitting samples, clickcreate impulse on the left column and I can start creating my models.
There are a few things should be considered during the process, like "window increase" here should not be higher than "window size" and the "MFCC" processing selcetion.
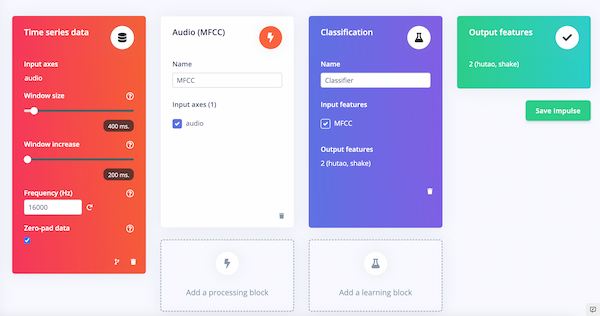
Setting can be changed here, and I can see the raw data converting to the featured data:
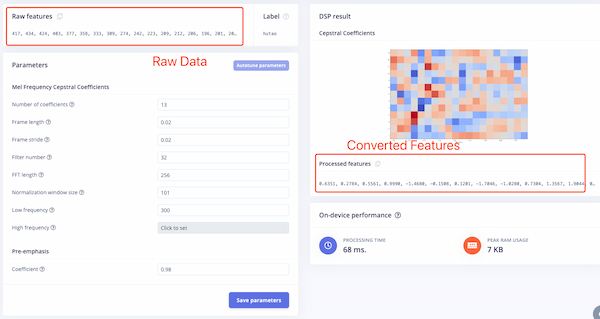
And parameters here should be adjusted to output the fine accuracy rate:
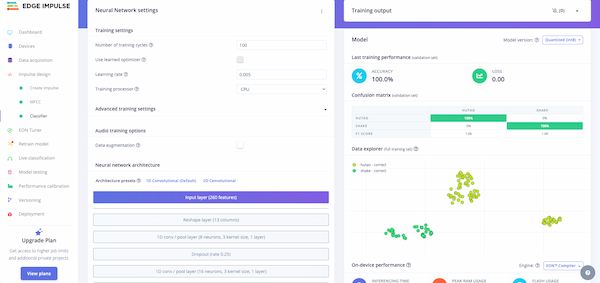
Here are some parameters explanning:
- Number of Training Cycles (Epochs): Optimize the number of epochs to avoid underfitting (too few epochs) and overfitting (too many epochs).
- Monitoring: Use validation loss to find the optimal number of epochs.
- Learning Rate: Adjust the learning rate to ensure the model converges efficiently without overshooting or stagnating.
- Adaptive Methods: Consider using adaptive learning rate techniques to improve convergence.
- Advanced Training Settings: Implement audio-specific transformations such as noise addition or pitch variation to improve model robustness.
Later using extra test files to test the model function:
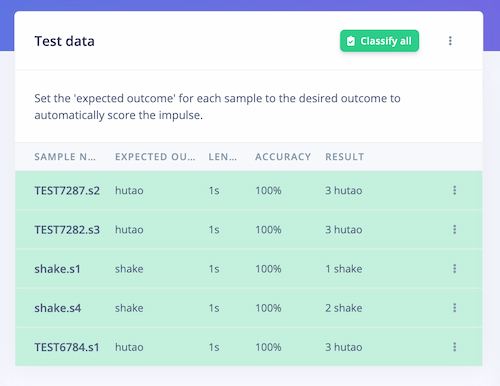
Looking good.
Then I can output the final model:
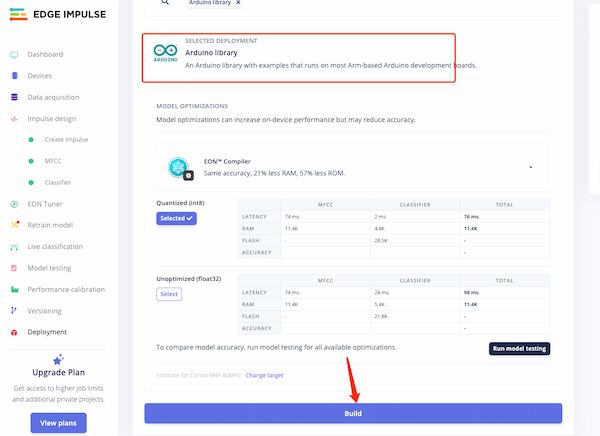
This will the file I needed:

Deploying on the board
Now I will use the the model to test on the real board. But first I need to add this model(library) into my Arduino:
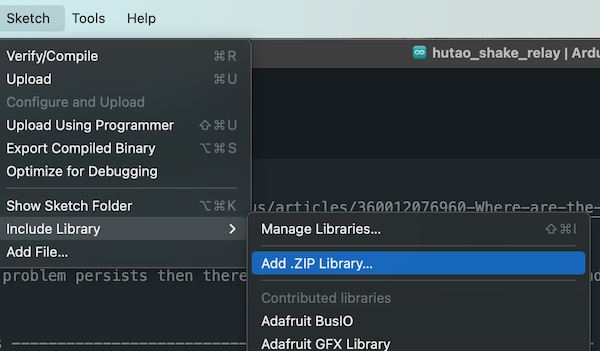
Then I run this code(which is also the example code from the library):
/* Edge Impulse ingestion SDK
* Copyright (c) 2022 EdgeImpulse Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
// If your target is limited in memory remove this macro to save 10K RAM
#define EIDSP_QUANTIZE_FILTERBANK 0
/**
* Define the number of slices per model window. E.g. a model window of 1000 ms
* with slices per model window set to 4. Results in a slice size of 250 ms.
* For more info: https://docs.edgeimpulse.com/docs/continuous-audio-sampling
*/
#define EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW 4
/*
** NOTE: If you run into TFLite arena allocation issue.
**
** This may be due to may dynamic memory fragmentation.
** Try defining "-DEI_CLASSIFIER_ALLOCATION_STATIC" in boards.local.txt (create
** if it doesn't exist) and copy this file to
** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.
**
** See
** (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)
** to find where Arduino installs cores on your machine.
**
** If the problem persists then there's not enough memory for this model and application.
*/
/* Includes ---------------------------------------------------------------- */
#include <PDM.h>
#include <Seeed_inferencing.h>
/** Audio buffers, pointers and selectors */
typedef struct {
signed short *buffers[2];
unsigned char buf_select;
unsigned char buf_ready;
unsigned int buf_count;
unsigned int n_samples;
} inference_t;
static inference_t inference;
static bool record_ready = false;
static signed short *sampleBuffer;
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static int print_results = -(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW);
/**
* @brief Arduino setup function
*/
void setup()
{
// put your setup code here, to run once:
Serial.begin(115200);
// comment out the below line to cancel the wait for USB connection (needed for native USB)
while (!Serial);
Serial.println("Edge Impulse Inferencing Demo");
// summary of inferencing settings (from model_metadata.h)
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: %.2f ms.\n", (float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) /
sizeof(ei_classifier_inferencing_categories[0]));
run_classifier_init();
if (microphone_inference_start(EI_CLASSIFIER_SLICE_SIZE) == false) {
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
}
/**
* @brief Arduino main function. Runs the inferencing loop.
*/
void loop()
{
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Failed to record audio...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_SLICE_SIZE;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier_continuous(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
if (++print_results >= (EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)) {
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: %.5f\n", result.classification[ix].label,
result.classification[ix].value);
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
print_results = 0;
}
}
/**
* @brief PDM buffer full callback
* Get data and call audio thread callback
*/
static void pdm_data_ready_inference_callback(void)
{
int bytesAvailable = PDM.available();
// read into the sample buffer
int bytesRead = PDM.read((char *)&sampleBuffer[0], bytesAvailable);
if (record_ready == true) {
for (int i = 0; i<bytesRead>> 1; i++) {
inference.buffers[inference.buf_select][inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
/**
* @brief Init inferencing struct and setup/start PDM
*
* @param[in] n_samples The n samples
*
* @return { description_of_the_return_value }
*/
static bool microphone_inference_start(uint32_t n_samples)
{
inference.buffers[0] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[0] == NULL) {
return false;
}
inference.buffers[1] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[1] == NULL) {
free(inference.buffers[0]);
return false;
}
sampleBuffer = (signed short *)malloc((n_samples >> 1) * sizeof(signed short));
if (sampleBuffer == NULL) {
free(inference.buffers[0]);
free(inference.buffers[1]);
return false;
}
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// configure the data receive callback
PDM.onReceive(&pdm_data_ready_inference_callback);
PDM.setBufferSize((n_samples >> 1) * sizeof(int16_t));
// initialize PDM with:
// - one channel (mono mode)
// - a 16 kHz sample rate
if (!PDM.begin(1, EI_CLASSIFIER_FREQUENCY)) {
ei_printf("Failed to start PDM!");
}
// set the gain, defaults to 20
PDM.setGain(127);
record_ready = true;
return true;
}
/**
* @brief Wait on new data
*
* @return True when finished
*/
static bool microphone_inference_record(void)
{
bool ret = true;
if (inference.buf_ready == 1) {
ei_printf(
"Error sample buffer overrun. Decrease the number of slices per model window "
"(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)\n");
ret = false;
}
while (inference.buf_ready == 0) {
delay(1);
}
inference.buf_ready = 0;
return ret;
}
/**
* Get raw audio signal data
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr)
{
numpy::int16_to_float(&inference.buffers[inference.buf_select ^ 1][offset], out_ptr, length);
return 0;
}
/**
* @brief Stop PDM and release buffers
*/
static void microphone_inference_end(void)
{
PDM.end();
free(inference.buffers[0]);
free(inference.buffers[1]);
free(sampleBuffer);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endif
The output seems fine:
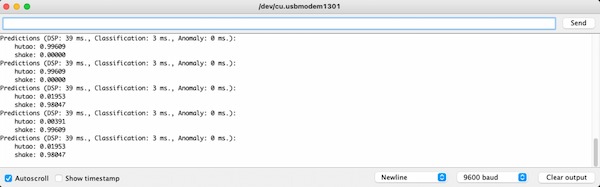
Integrating it with relay
Finally, I will integrate it with a relay to control my toy:

And do a little change about the previous code:
/* Edge Impulse ingestion SDK
* Copyright (c) 2022 EdgeImpulse Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
// If your target is limited in memory remove this macro to save 10K RAM
#define EIDSP_QUANTIZE_FILTERBANK 0
/**
* Define the number of slices per model window. E.g. a model window of 1000 ms
* with slices per model window set to 4. Results in a slice size of 250 ms.
* For more info: https://docs.edgeimpulse.com/docs/continuous-audio-sampling
*/
#define EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW 4
/*
** NOTE: If you run into TFLite arena allocation issue.
**
** This may be due to may dynamic memory fragmentation.
** Try defining "-DEI_CLASSIFIER_ALLOCATION_STATIC" in boards.local.txt (create
** if it doesn't exist) and copy this file to
** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.
**
** See
** (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)
** to find where Arduino installs cores on your machine.
**
** If the problem persists then there's not enough memory for this model and application.
*/
/* Includes ---------------------------------------------------------------- */
#include <PDM.h>
#include <Seeed_inferencing.h>
int NUMBER_CLASSES = 2;
/** Audio buffers, pointers and selectors */
typedef struct {
signed short *buffers[2];
unsigned char buf_select;
unsigned char buf_ready;
unsigned int buf_count;
unsigned int n_samples;
} inference_t;
static inference_t inference;
static bool record_ready = false;
static signed short *sampleBuffer;
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static int print_results = -(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW);
/**
* @brief Arduino setup function
*/
void setup()
{
pinMode(D1, OUTPUT);
// put your setup code here, to run once:
Serial.begin(115200);
// comment out the below line to cancel the wait for USB connection (needed for native USB)
while (!Serial);
Serial.println("Edge Impulse Inferencing Demo");
// summary of inferencing settings (from model_metadata.h)
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: %.2f ms.\n", (float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) /
sizeof(ei_classifier_inferencing_categories[0]));
run_classifier_init();
if (microphone_inference_start(EI_CLASSIFIER_SLICE_SIZE) == false) {
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
}
/**
* @brief Arduino main function. Runs the inferencing loop.
*/
void shake_hutao(int pred_index){
switch (pred_index){
case 0:
digitalWrite(D1, LOW);
break;
case 1:
digitalWrite(D1, HIGH);
break;
case 2:
ei_printf("here");
break;
}
}
void loop()
{
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Failed to record audio...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_SLICE_SIZE;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier_continuous(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
if (++print_results >= (EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)) {
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
int pred_index = 2; // Initialize pred_index
float pred_value = 0.8; // Initialize pred_value
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: %.5f\n", result.classification[ix].label,
result.classification[ix].value);
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
shake_hutao(pred_index);
ei_printf(": \n");
ei_printf("%d",pred_index);
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
print_results = 0;
}
}
/**
* @brief PDM buffer full callback
* Get data and call audio thread callback
*/
static void pdm_data_ready_inference_callback(void)
{
int bytesAvailable = PDM.available();
// read into the sample buffer
int bytesRead = PDM.read((char *)&sampleBuffer[0], bytesAvailable);
if (record_ready == true) {
for (int i = 0; i<bytesRead>> 1; i++) {
inference.buffers[inference.buf_select][inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
/**
* @brief Init inferencing struct and setup/start PDM
*
* @param[in] n_samples The n samples
*
* @return { description_of_the_return_value }
*/
static bool microphone_inference_start(uint32_t n_samples)
{
inference.buffers[0] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[0] == NULL) {
return false;
}
inference.buffers[1] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[1] == NULL) {
free(inference.buffers[0]);
return false;
}
sampleBuffer = (signed short *)malloc((n_samples >> 1) * sizeof(signed short));
if (sampleBuffer == NULL) {
free(inference.buffers[0]);
free(inference.buffers[1]);
return false;
}
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// configure the data receive callback
PDM.onReceive(&pdm_data_ready_inference_callback);
PDM.setBufferSize((n_samples >> 1) * sizeof(int16_t));
// initialize PDM with:
// - one channel (mono mode)
// - a 16 kHz sample rate
if (!PDM.begin(1, EI_CLASSIFIER_FREQUENCY)) {
ei_printf("Failed to start PDM!");
}
// set the gain, defaults to 20
PDM.setGain(127);
record_ready = true;
return true;
}
/**
* @brief Wait on new data
*
* @return True when finished
*/
static bool microphone_inference_record(void)
{
bool ret = true;
if (inference.buf_ready == 1) {
ei_printf(
"Error sample buffer overrun. Decrease the number of slices per model window "
"(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)\n");
ret = false;
}
while (inference.buf_ready == 0) {
delay(1);
}
inference.buf_ready = 0;
return ret;
}
/**
* Get raw audio signal data
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr)
{
numpy::int16_to_float(&inference.buffers[inference.buf_select ^ 1][offset], out_ptr, length);
return 0;
}
/**
* @brief Stop PDM and release buffers
*/
static void microphone_inference_end(void)
{
PDM.end();
free(inference.buffers[0]);
free(inference.buffers[1]);
free(sampleBuffer);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endif
The outcome:
Reference: Toy Assemble
The toy is referenced by an anchor named: 机智的 Kason and here is the assembling steps.
Here is the 2D files.