Local LLM and Auto-generation tsx file
Write something in advance
Written on 4.17th, there are several steps required to achieve my project, in this potion, I am going to implement the necessary function, in the very raw ways.
- Implement the LLM deployed locally
- Apply the local LLM API and store the text file, with setup standard format, using Python
- Auto-generate the page files of calendar, with detailed description of the task and time, using Python
Implement the LLM deployed locally
I am using Ollama which supports multiple platform. Since my reComputer J4012 is not arrived, I can use my Mac to test some progress of the final.
The installation is pretty simple. For MacOS, using this link can download directly. When the reComputer arrived, I can use this commend:
curl -fsSL https://ollama.com/install.sh | sh
to install it.
Then choose Gemma for the simple test, using these commend to run it:
ollama pull gemma
ollama run gemma
Here is the output:
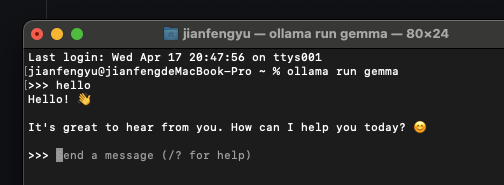
Since I am going to use it to achieve auto-generation of some files. I need to use its API, also I need to write an application - I am planning to use Python.
Ollama API
In the GitHub repository of Ollama, there presents the usage of Ollama API. For using the Application Programming Interface, I understand that I need to find the port that the Ollama is listened:
Why does the API need to use a specific port?
- Isolation and security: By running API services on a specific port, network security Settings can be simplified, for example, that port can be monitored and secured specifically to prevent insecure access.
- Organization and management: If you are running multiple services on the same server, assigning different ports can help you manage these services. For example, your main website might be running on port 80 and an API service might be running on another port.
- Avoid conflicts: Using non-standard ports can prevent port conflicts. In a development environment, there may be multiple applications or services that need to be running at the same time, and using different ports ensures that they don't interfere with each other.
From this document, I know that Ollama binds 127.0.0.1 port 11434 by default, and I can change the bind address with the OLLAMA_HOST environment variable.
I use the commend to find it:
sudo lsof -i :11434
To make sure the port is listened by the ollama.
I can use these commend to achieve the API calling:
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Why is the sky blue?"
}'
as long as I change the right port and the model. Then it can output the answer to my question("prompt"):
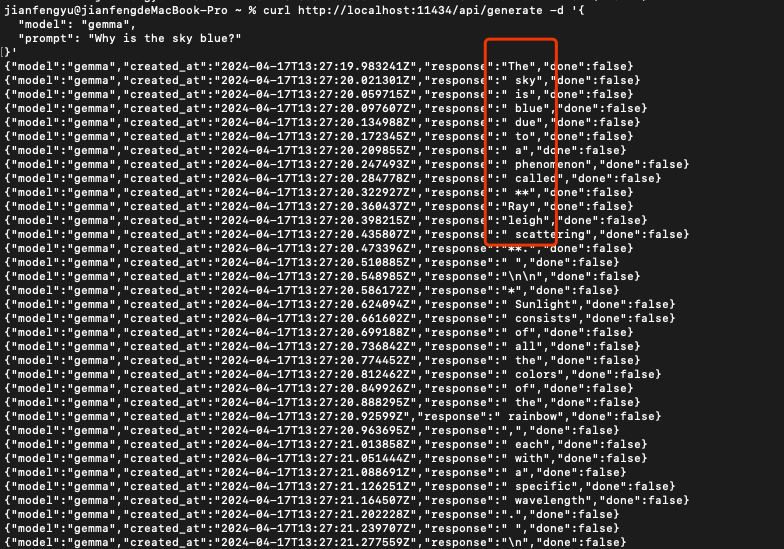
wirtting in json format. There are other parameters for the changing so I can have the different output:
format: the format to return a response in. Currently the only accepted value isjsonoptions: additional model parameters listed in the documentation for the Modelfile such astemperaturesystem: system message to (overrides what is defined in theModelfile)template: the prompt template to use (overrides what is defined in theModelfile)context: the context parameter returned from a previous request to/generate, this can be used to keep a short conversational memorystream: iffalsethe response will be returned as a single response object, rather than a stream of objectsraw: iftrueno formatting will be applied to the prompt. You may choose to use therawparameter if you are specifying a full templated prompt in your request to the APIkeep_alive: controls how long the model will stay loaded into memory following the request (default:5m)
These will be helpful for my converting.
Store the text file with standard format, using Python
I found an example from Seeed Studio's repo(open source): Real-time-Subtitle-Recorder-on-Jetson. It applies Riva ASR Server(supported by reComputer J4012) to capture data from the microphone input in real-time and display it on a webpage. - pretty good project and somehow match my projectXD
I first want to apply the Ollama API and use Python to achieve the standard format text file. Then I want to change the code of it, by removing the Riva and webpage(flask) parts, using GPT:
import requests
import time
class Ollama:
def __init__(self, prompt, output_file):
self.prompt = prompt
self.output_file = output_file
def generate_text(self):
url = "http://localhost:11434/api/generate"
data = {
"model": "gemma",
"prompt": self.prompt,
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
result = response.json()
generated_text = result['response']
self.save_to_file(generated_text)
print("Generated text saved to file.")
print("Total duration:", result['total_duration'])
print("Load duration:", result['load_duration'])
print("Prompt eval count:", result['prompt_eval_count'])
print("Prompt eval duration:", result['prompt_eval_duration'])
print("Eval count:", result['eval_count'])
print("Eval duration:", result['eval_duration'])
else:
print("Error calling ollama API:", response.status_code)
def save_to_file(self, text):
with open(self.output_file, 'w') as file:
file.write(text)
if __name__ == '__main__':
prompt = "hello send the message of my calendar 'I will do the task 1 on Saturday. front: today is friday with 2024.2.20' as a format, including 'time:' and 'task detail:', and the content of time should be lookling like this: `(2021, 5, 8)`"
output_file = "output.txt"
ollama = Ollama(prompt, output_file)
ollama.generate_text()
I set the stream as false to call the Ollama API, to ensure there just one character type(response) containing. The others are just presented in the Terminal, to make sure it is workable and I can call them anytime.
The prompt is the most important thing and it can help me output the format of what I want - I can then directly use the answer from LLM to have my standard format text file.
After all sets up, I run this commend and the Terminal looks like this:
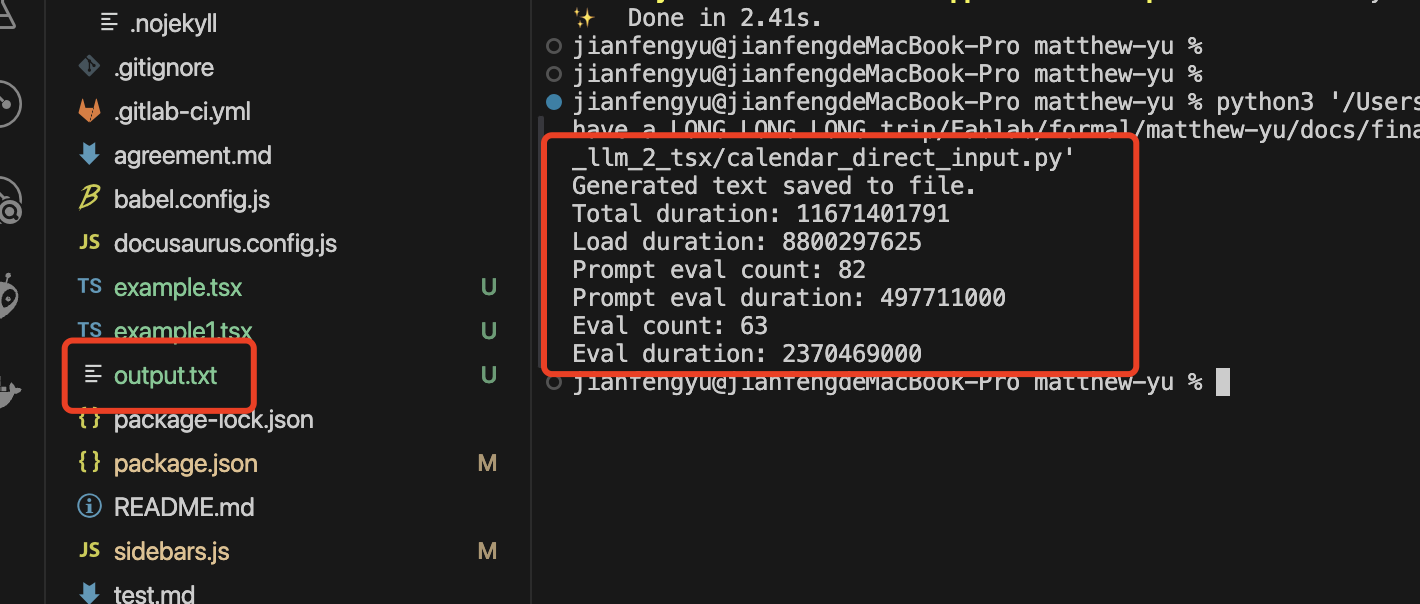
And I have find a text file under the path and when opens it:
**Today is Friday, February 20, 2024.**
**Time:** (2024, 2, 20)
**Task detail:** I will do the task 1 on Saturday.
It works! With the file under the standard format, I can do so much thing right now!
Auto-generate the page files
Introduce the UI I am using
I am using Docusaurus! same as my GitLab website! It is pretty good web-generation platform and has so many extensions. For example: the cusomizable calendar - "DayPicker".
And the installation is pretty simple:
npm install react-day-picker date-fns # with npm
pnpm install react-day-picker date-fns # with pnpm
yarn add react-day-picker date-fns # with yarn
These three commands all support the installation and I use yarn add to install it. After some time, the package.json will contain the its dependencies and I can use it.
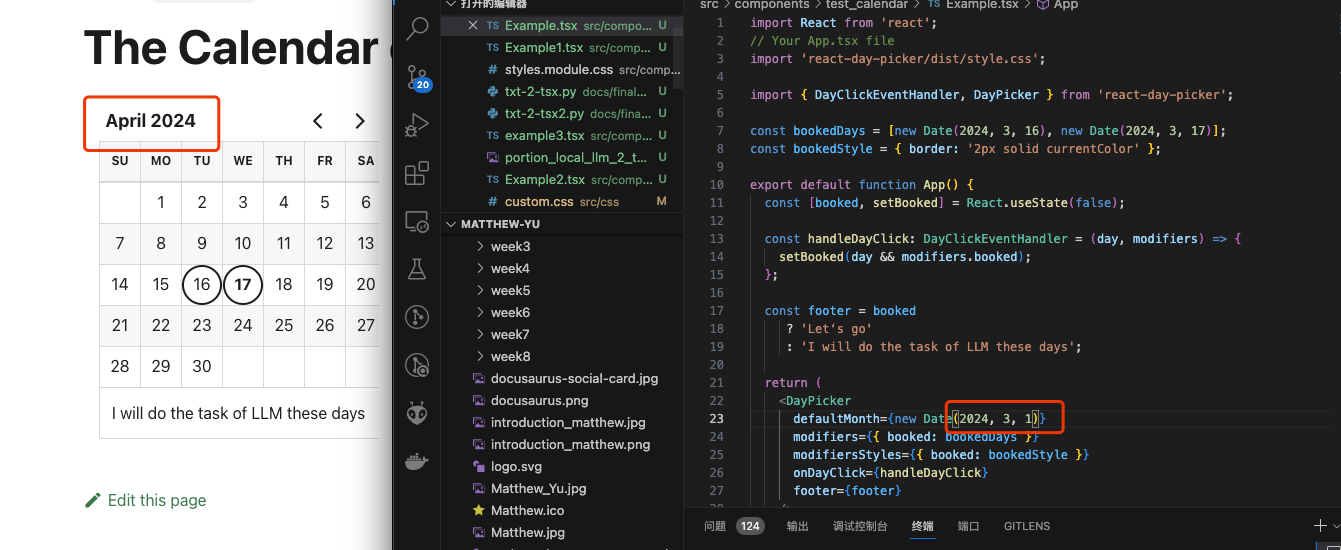
Since it supports TSX format file. I need to add some components under the path: /src/somponents/(folder that store it)
import React from 'react';
// Your App.tsx file
import 'react-day-picker/dist/style.css';
import { DayClickEventHandler, DayPicker } from 'react-day-picker';
const bookedDays = [new Date(2021, 5, 8), new Date(2021, 5, 9)];
const bookedStyle = { border: '2px solid currentColor' };
export default function App() {
const [booked, setBooked] = React.useState(false);
const handleDayClick: DayClickEventHandler = (day, modifiers) => {
setBooked(day && modifiers.booked);
};
const footer = booked
? 'Let‘s go'
: 'I will do the task 1 these days';
return (
<DayPicker
defaultMonth={new Date(2021, 5, 8)}
modifiers={{ booked: bookedDays }}
modifiersStyles={{ booked: bookedStyle }}
onDayClick={handleDayClick}
footer={footer}
/>
);
}
Then I need to creat a ".mdx" file and call it and make it visible. Writing it is simliar to ".md" but includes more functions:
MDX and Markdown (MD) are two different formats primarily used for writing and rendering textual content. Although they share many similarities, MDX extends the capabilities of Markdown by incorporating additional features, particularly the ability to use JSX (JavaScript XML) components directly within Markdown text. This makes MDX highly suitable for scenarios where integrating React components directly into Markdown documents is desired.
Directly input is not exhitbited well, I still need to input some style files( such as .css files), change the custom.css for the global changing. Finally I can have the calendar with my task on it and it can present on my web page.
The most interesting thing is that I find that I only change the footer and bookedDays that I can have my plans presented(pretty raw way).
Adding auto-generate function for my previoous Python code
I now have the function of "auto-generating the text file" and I have the template files of TSX page. I then can auto-generate my TSX page(the components):
I add a funtion update_tsx_file in it:
- Read the text file from the previous output
- Extact the format contents(
**Time:**and**Task Detail:**) that I need - Set up the TSX template, and set the varables:
booked_daysandfooter_text - Parse the content and return them to the "parse_time"
- Finally replace the parsed content to
booked_daysandfooter_text
And the final one is:
import requests
import time
import re
import os
class Ollama:
def __init__(self, prompt, output_file, tsx_file):
self.prompt = prompt
self.output_file = output_file
self.tsx_file = tsx_file
def generate_text(self):
url = "http://localhost:11434/api/generate"
data = {
"model": "gemma",
"prompt": self.prompt,
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
result = response.json()
generated_text = result['response']
self.save_to_file(generated_text)
print("Generated text saved to file.")
self.update_tsx_file()
else:
print("Error calling ollama API:", response.status_code)
def save_to_file(self, text):
with open(self.output_file, 'w') as file:
file.write(text)
def update_tsx_file(self):
with open(self.output_file, 'r') as file:
content = file.read()
time_match = re.search(r'\*\*Time:\*\*\s*(.*)', content)
task_match = re.search(r'\*\*Task Detail:\*\*\s*(.*)', content)
if time_match and task_match:
time_str = time_match.group(1)
task_detail = task_match.group(1)
booked_days = self.parse_time(time_str)
footer_text = task_detail
tsx_content = f'''
import React from 'react';
import 'react-day-picker/dist/style.css';
import {{ DayClickEventHandler, DayPicker }} from 'react-day-picker';
const bookedDays = {booked_days};
const bookedStyle = {{ border: '2px solid currentColor' }};
export default function App() {{
const [booked, setBooked] = React.useState(false);
const handleDayClick: DayClickEventHandler = (day, modifiers) => {{
setBooked(day && modifiers.booked);
}};
const footer = booked
? '{footer_text}'
: '222.';
return (
<DayPicker
defaultMonth={{new Date(2021, 5, 8)}}
modifiers={{{{ booked: bookedDays }}}}
modifiersStyles={{{{ booked: bookedStyle }}}}
onDayClick={{handleDayClick}}
footer={{footer}}
/>
);
}}
'''
tsx_file = self.get_unique_filename(self.tsx_file)
with open(self.tsx_file, 'w') as file:
file.write(tsx_content)
print("TSX file updated.")
else:
print("Required information not found in the output file.")
def get_unique_filename(self, filename):
name, ext = os.path.splitext(filename)
counter = 1
while os.path.exists(filename):
filename = f"{name}{counter}{ext}"
counter += 1
return filename
def parse_time(self, time_str):
# 根据实际的时间格式进行解析,返回bookedDays的格式
# 这里假设时间格式为 "YYYY-MM-DD"
dates = time_str.split(',')
booked_days = []
for date in dates:
date = date.strip()
year, month, day = map(int, date.split('-'))
booked_days.append(f"new Date({year}, {month - 1}, {day})")
return f"[{', '.join(booked_days)}]"
if __name__ == '__main__':
prompt = "Today is 2024-2-20, Friday, I am going to do my task 1 on Saturday . Please provide the time and task detail in the following format:\n**Time:** YYYY-MM-DD, YYYY-MM-DD\n**Task Detail:** Your task detail here; if you don't know, just output the format anyway"
output_file = "output.txt"
tsx_file = "src/components/test_calendar/example.tsx"
ollama = Ollama(prompt, output_file, tsx_file)
ollama.generate_text()
The outcome is successfully:
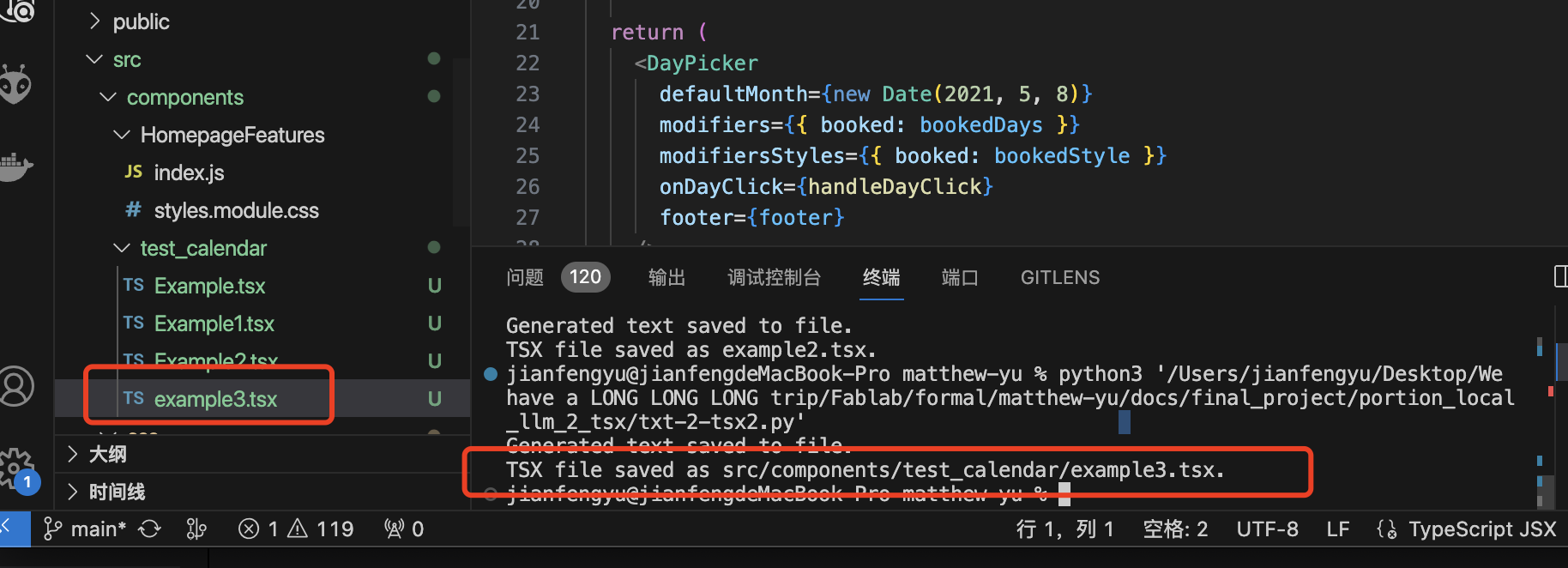
Additional function: Case of batch generation
What I want to achieve is that the divice can recognize my voice input, continously. So the continous output is necessary, and it might be the case of batch generation.
So I add a new function called get_unique_filename() and let it read the name of TSX file, and then let it continously check if the name of the file is existent. If the name exists, then it add the count to the end of the file:
example.tsx
example1.tsx
example2.tsx
...
This will ensure the tasks been added up every time the LLM recognized.
The outcome is:
Still need to do
- Improve the UI of calendar(if I have more time)
- Make full-screen
- change and add contents on one calendar not multiple
- Fix some data bugs
- Build my own API interface, with speech recognition, and turn
promptinto the corresponding variable