3. Software
3.1. Requirement Analysis
3.1.1 Hardware Requirements
- Main Control Unit: Xiao ESP32-S3
- Sensors/Devices:
- Microphone: Capture audio and recognize specific trigger phrases (e.g., "How many people are ahead?").
- Camera: Capture photos and send them to the main control unit for processing.
- Display: Show the results of recognition (e.g., text or images).
- Speaker: Play audio feedback with recognition results.
- WiFi Module: Connect to the internet for processing and cloud interaction (e.g., uploading photos or remote recognition).
3.1.2 Software Requirements
- User Interface:
- Simple and intuitive interface for interaction.
- Display recognition results clearly.
- Voice Recognition Module:
- Capture audio using the microphone.
- Recognize trigger words or phrases (e.g., “How many people are ahead?”).
- Image Processing Module:
- Capture a photo and send it to the processing unit.
- Use an image recognition model (e.g., TensorFlow Lite) to analyze the photo and recognize objects or scenes.
- Display Module:
- Show the recognition results (e.g., text, image).
- Voice Feedback Module (optional):
- Play audio feedback based on the recognition results.
- Wi-Fi Module:
- Connect to the internet, possibly for remote control or uploading recognition results.
- Power Management:
- Provide stable power to ensure continuous operation of the device.
3.1.3 Functional Requirements
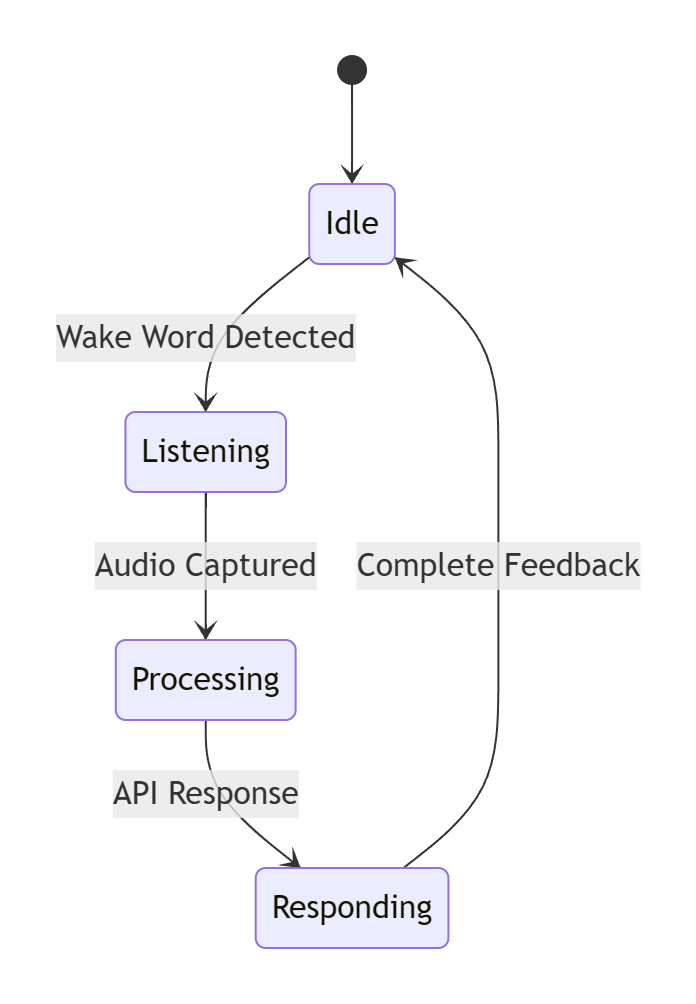
- Startup & Connection: The device should automatically connect to the Wi-Fi network upon startup and wait for microphone input.
- Voice Trigger: Trigger photo capture and image recognition via specific voice commands.
- Image Recognition: Recognize people, objects, or scenes in the captured photo and return results.
- Voice Feedback (optional): Play feedback information via the speaker based on the recognition results.
- Display Results: Display the recognition results on the screen.
3.1.4 Performance Requirements
- Latency: The latency of voice recognition and image processing should be as low as possible for a smooth user experience.
- Accuracy: The voice and image recognition accuracy must be high to ensure the device can recognize trigger words and objects accurately.
3.2 System Architecture
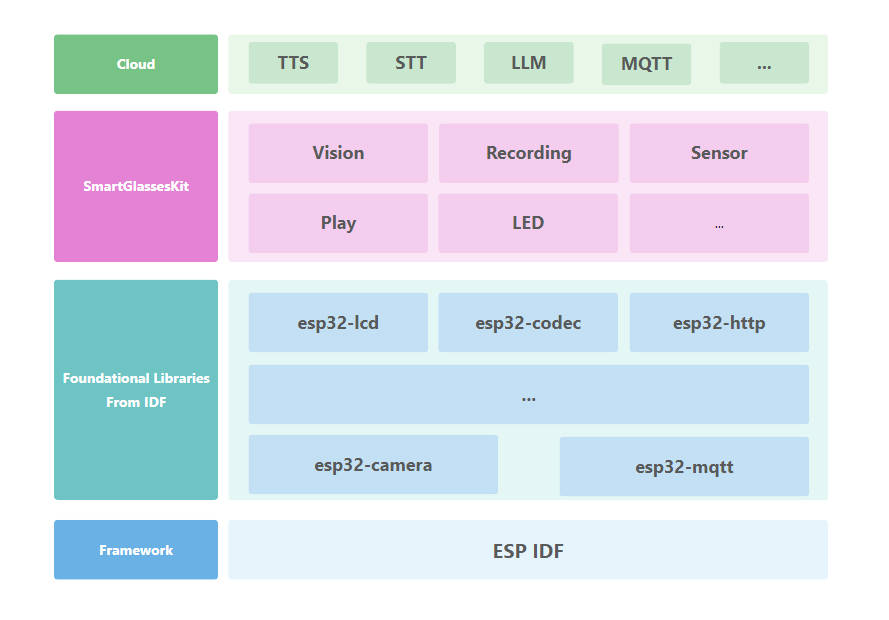
The Smart Glasses Kit is an open-source software project that enables a compact wearable device to interact with the world using natural language and visual understanding. It leverages powerful AI models through server integration to enable intelligent interaction via voice and camera input.
This system is based on the Xiaozhi-ESP32 platform and communicates with a backend service, xiaozhi-esp32-server, both of which are licensed under the MIT License.
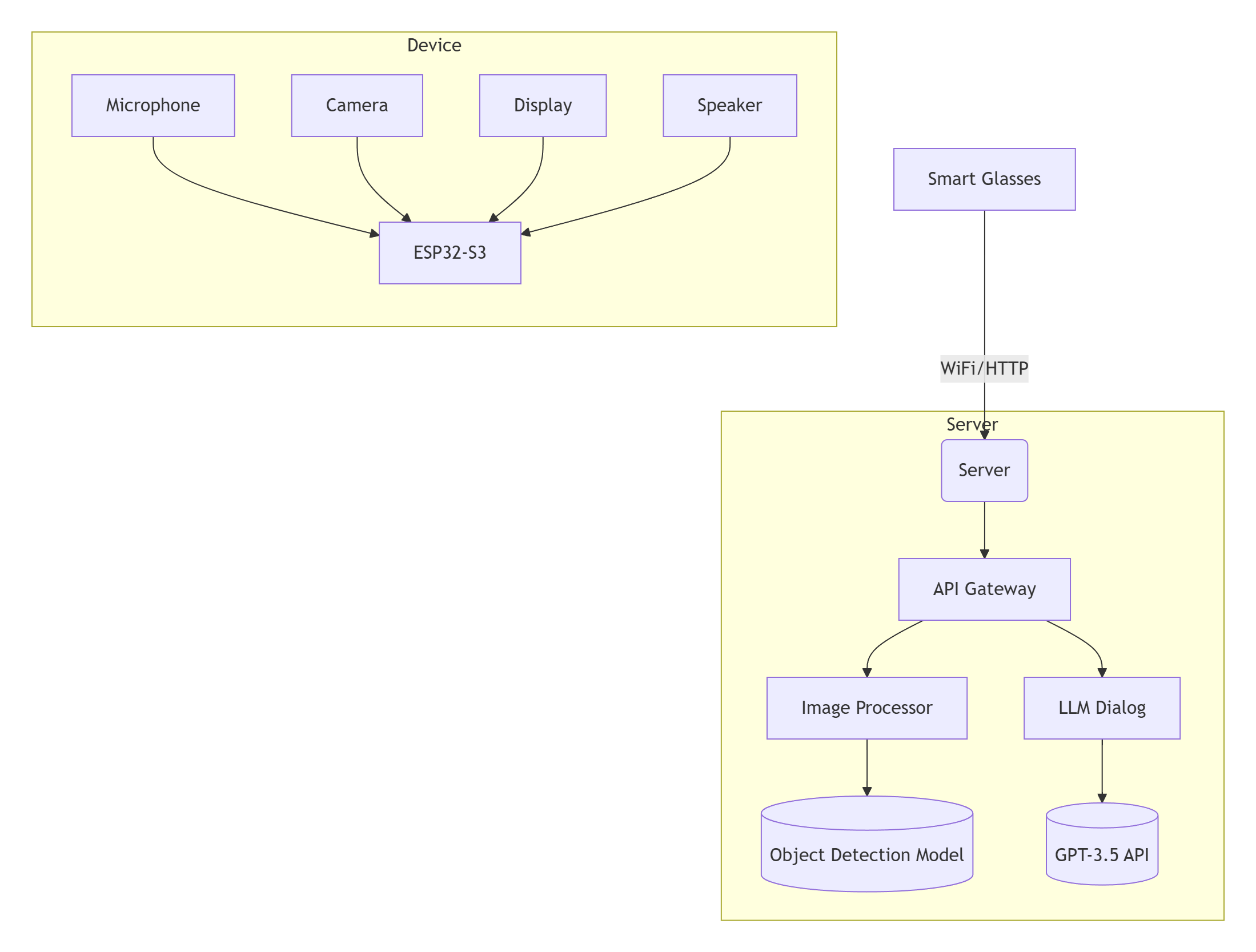
3.2.1 Device Firmware Architecture
- Porting the xiaozhi-esp32 to Smart Glasses Kit
#include "wifi_board.h"
#include "system_reset.h"
#include "application.h"
#include "button.h"
#include "config.h"
#include "iot/thing_manager.h"
#include "led/single_led.h"
#include "assets/lang_config.h"
#include <esp_lcd_panel_io.h>
#include <esp_lcd_panel_ops.h>
#include "audio_codecs/no_audio_codec.h"
#include "display/lcd_display.h"
#include "camera/camera.h"
#include "esp_lcd_gc9107.h"
#include "touch_element/touch_button.h"
#include "mbedtls/base64.h"
#include <esp_log.h>
#include <driver/i2c_master.h>
#include <esp_lcd_panel_ops.h>
#include <esp_lcd_panel_vendor.h>
#include <wifi_station.h>
#define TAG "SmartGlasses"
LV_FONT_DECLARE(font_puhui_14_1);
LV_FONT_DECLARE(font_awesome_14_1);
class SmartGlasses : public WifiBoard
{
private:
esp_lcd_panel_io_handle_t panel_io_ = nullptr;
esp_lcd_panel_handle_t panel_ = nullptr;
Button *button_ = nullptr;
Display *display_ = nullptr;
Camera *camera_ = nullptr;
void InitializeDisplaySPI()
{
ESP_LOGI(TAG, "Initialize SPI bus");
spi_bus_config_t buscfg = GC9107_PANEL_BUS_SPI_CONFIG(DISPLAY_SPI_SCLK_PIN, DISPLAY_SPI_MOSI_PIN,
128 * 128 * sizeof(uint16_t));
ESP_ERROR_CHECK(spi_bus_initialize(DISPLAY_SPI_NUM, &buscfg, SPI_DMA_CH_AUTO));
return;
}
void InitializeGC9107Display()
{
ESP_LOGI(TAG, "Init GC9107 display");
// Initialize SPI bus
ESP_LOGI(TAG, "Install panel IO");
esp_lcd_panel_io_handle_t io_handle = NULL;
esp_lcd_panel_io_spi_config_t io_config = GC9107_PANEL_IO_SPI_CONFIG(DISPLAY_SPI_CS_PIN, DISPLAY_SPI_DC_PIN, NULL, NULL);
io_config.pclk_hz = DISPLAY_PIXEL_CLK_HZ;
ESP_ERROR_CHECK(esp_lcd_new_panel_io_spi(DISPLAY_SPI_NUM, &io_config, &io_handle));
ESP_LOGI(TAG, "Install GC9107 panel driver");
esp_lcd_panel_handle_t panel_handle = NULL;
esp_lcd_panel_dev_config_t panel_config = {};
panel_config.reset_gpio_num = DISPLAY_SPI_RST_PIN; // Set to -1 if not use
panel_config.rgb_endian = DISPLAY_RGB_ELEMENT_ORDER; // LCD_RGB_ENDIAN_RGB;
panel_config.bits_per_pixel = DISPLAY_BITS_PER_PIXEL; // Implemented by LCD command `3Ah` (16/18)
ESP_ERROR_CHECK(esp_lcd_new_panel_gc9107(io_handle, &panel_config, &panel_handle));
ESP_ERROR_CHECK(esp_lcd_panel_reset(panel_handle));
ESP_ERROR_CHECK(esp_lcd_panel_init(panel_handle));
ESP_ERROR_CHECK(esp_lcd_panel_invert_color(panel_handle, true));
ESP_ERROR_CHECK(esp_lcd_panel_mirror(panel_handle, true, false));
ESP_ERROR_CHECK(esp_lcd_panel_disp_on_off(panel_handle, true));
// fill black screen
ESP_LOGI(TAG, "Fill screen");
// draw black screen
std::vector<uint16_t> buffer(129, 0x0000);
for (int y = 0; y <= 128; y++)
{
esp_lcd_panel_draw_bitmap(panel_handle, 0, y, 129, y + 1, buffer.data());
}
display_ = new SpiLcdDisplay(io_handle, panel_handle,
DISPLAY_WIDTH, DISPLAY_HEIGHT, DISPLAY_OFFSET_X, DISPLAY_OFFSET_Y, DISPLAY_MIRROR_X, DISPLAY_MIRROR_Y, DISPLAY_SWAP_XY,
{
.text_font = &font_puhui_14_1,
.icon_font = &font_awesome_14_1,
.emoji_font = font_emoji_64_init(),
});
display_->SetTheme("dark");
return;
}
void InitializeButtons()
{
button_ = new Button(BUILTIN_BTN_GPIO);
button_->OnLongPress([this]()
{
auto& app = Application::GetInstance();
static bool enabled = false;
enabled = !enabled;
ESP_LOGI(TAG, "Double click %s audio", enabled? "on" : "off");
this->GetAudioCodec()->EnableOutput(enabled); });
button_->OnClick([this]()
{
ESP_LOGI(TAG, "Click");
auto& app = Application::GetInstance();
if(!WifiStation::GetInstance().IsConnected()) {
ESP_LOGI(TAG, "Please Configure Device First");
return;
}
app.Schedule([this](){
Camera* camera = this->GetCamera();
Application& app = Application::GetInstance();
if (camera) {
camera_fb_t *fb = NULL;
size_t _jpg_buf_len;
uint8_t *_jpg_buf;
uint8_t *base64_buf = (uint8_t *)malloc(256 * 1024); // base64_buf needs to be at least 48*1024 bytes
size_t base64_buf_len;
camera->Capture(1000);
camera->RetrieveFrame(&fb);
bool jpeg_converted = frame2jpg(fb, 50, &_jpg_buf, &_jpg_buf_len);
mbedtls_base64_encode(base64_buf, 256 * 1024, &base64_buf_len, _jpg_buf, _jpg_buf_len);
app.ImageInvoke((const char*)base64_buf, base64_buf_len);
free(_jpg_buf);
free(base64_buf);
camera->ReturnFrame(fb);
}
}); });
return;
}
void InitializeIot()
{
auto &thing_manager = iot::ThingManager::GetInstance();
thing_manager.AddThing(iot::CreateThing("Speaker"));
thing_manager.AddThing(iot::CreateThing("Screen"));
}
// InitializeCamera
void InitializeCamera()
{
static camera_config_t camera_config = {
.pin_pwdn = CAM_PIN_PWDN,
.pin_reset = CAM_PIN_RESET,
.pin_xclk = CAM_PIN_XCLK,
.pin_sccb_sda = CAM_PIN_SIOD,
.pin_sccb_scl = CAM_PIN_SIOC,
.pin_d7 = CAM_PIN_D7,
.pin_d6 = CAM_PIN_D6,
.pin_d5 = CAM_PIN_D5,
.pin_d4 = CAM_PIN_D4,
.pin_d3 = CAM_PIN_D3,
.pin_d2 = CAM_PIN_D2,
.pin_d1 = CAM_PIN_D1,
.pin_d0 = CAM_PIN_D0,
.pin_vsync = CAM_PIN_VSYNC,
.pin_href = CAM_PIN_HREF,
.pin_pclk = CAM_PIN_PCLK,
.xclk_freq_hz = 20000000,
.ledc_timer = LEDC_TIMER_0,
.ledc_channel = LEDC_CHANNEL_0,
.frame_size = FRAMESIZE_VGA,
.jpeg_quality = 12, // 0-63, for OV series camera sensors, lower number means higher quality
.fb_count = 1, // When jpeg mode is used, if fb_count more than one, the driver will work in continuous mode.
.fb_location = CAMERA_FB_IN_PSRAM,
.grab_mode = CAMERA_GRAB_WHEN_EMPTY,
};
camera_ = new EspCamera(camera_config);
return;
}
public:
SmartGlasses()
{
InitializeDisplaySPI();
InitializeGC9107Display();
InitializeCamera();
InitializeButtons();
InitializeIot();
}
virtual Led *GetLed() override
{
static SingleLed led(BUILTIN_LED_GPIO);
return &led;
}
virtual AudioCodec *GetAudioCodec() override
{
static NoAudioCodecSimplexPdm audio_codec(AUDIO_INPUT_SAMPLE_RATE, AUDIO_OUTPUT_SAMPLE_RATE,
AUDIO_I2S_SPK_GPIO_BCLK, AUDIO_I2S_SPK_GPIO_LRCK, AUDIO_I2S_SPK_GPIO_DOUT, AUDIO_I2S_MIC_GPIO_WS, AUDIO_I2S_MIC_GPIO_DIN);
return &audio_codec;
}
virtual Display *GetDisplay() override
{
return display_;
}
virtual Camera *GetCamera() override
{
return camera_;
}
};
DECLARE_BOARD(SmartGlasses);
- Add Image Recognition Functionality to the
xiaozhi-esp32Project
void Protocol::SendImage(const char *data, size_t length) {
std::string message = "{\"session_id\":\"" + session_id_ + "\",\"type\":\"image\",\"image\":\"" + std::string(data, length) + "\"}";
SendText(message);
}
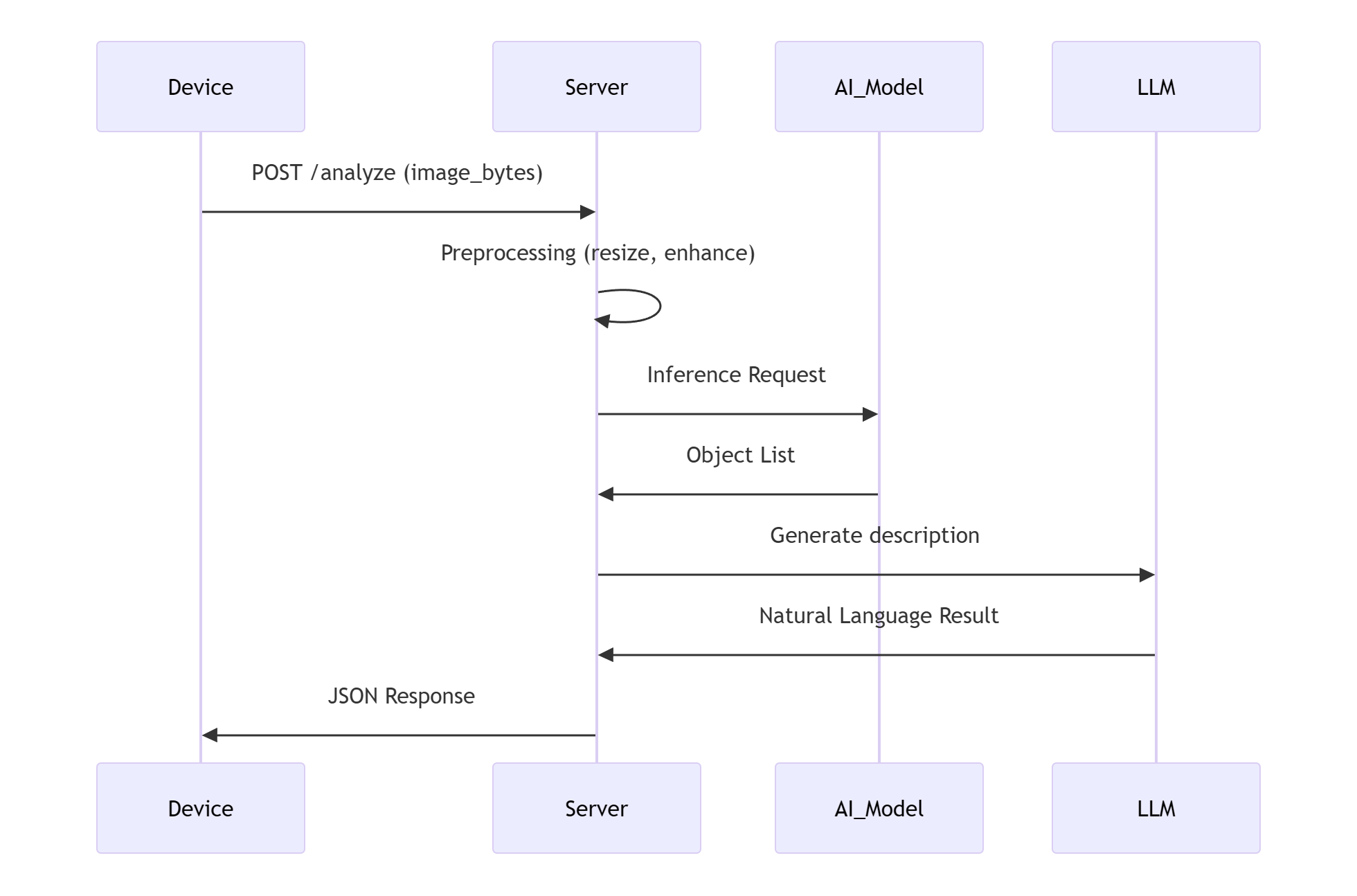
3.2.2 Server Architecture

- Add Image Recognition Functionality to the
xiaozhi-esp32-serverProject
import requests
import json
import urllib
def handleImage(conn, text, image):
result = None
# Token
url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
headers = {
"Authorization": "XXXXXX",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4v-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image,
}
},
{
"type": "text",
"text": text
}
]
}
]
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
result = response.json()
print(result)
else:
print(f"Failed: {response.status_code} : {response.text}")
return result
3.5 Testing
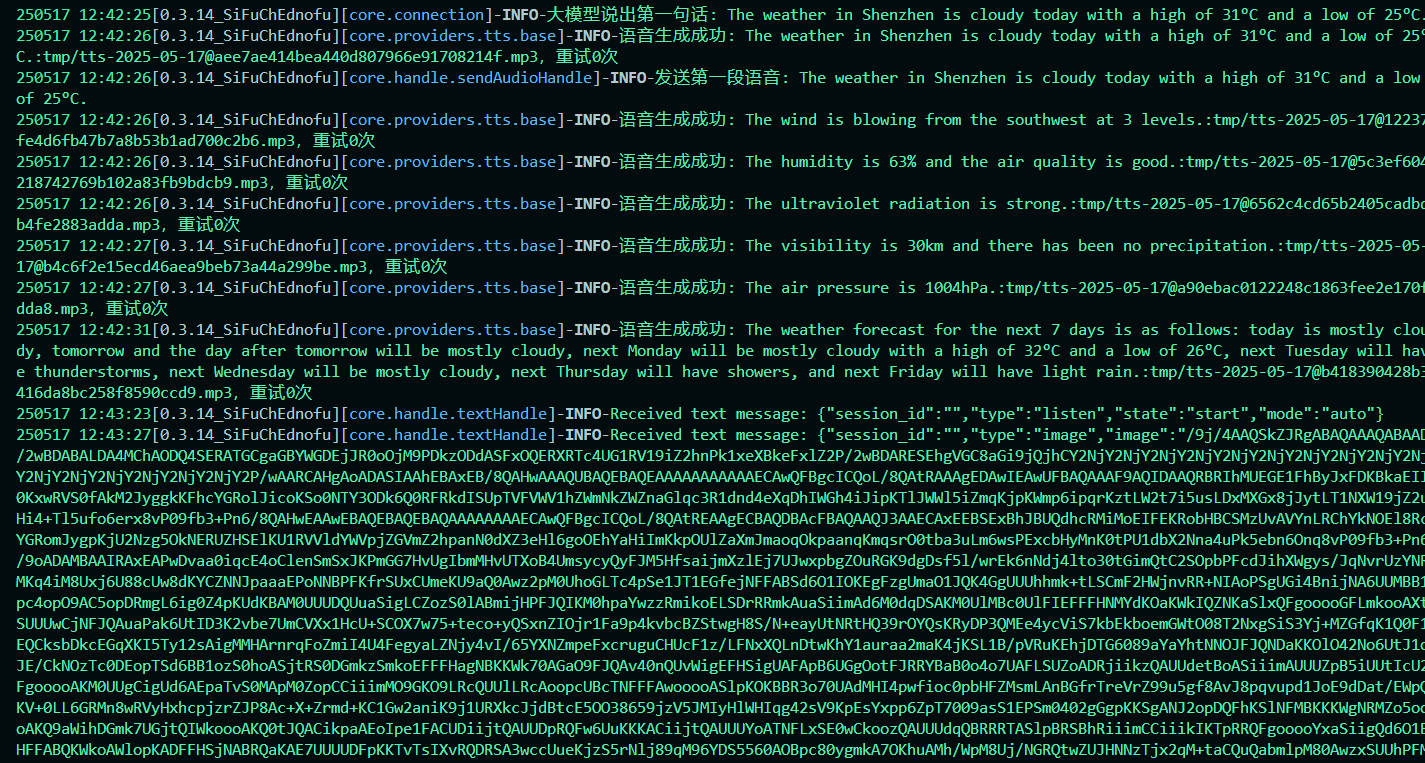
- Comunication Function
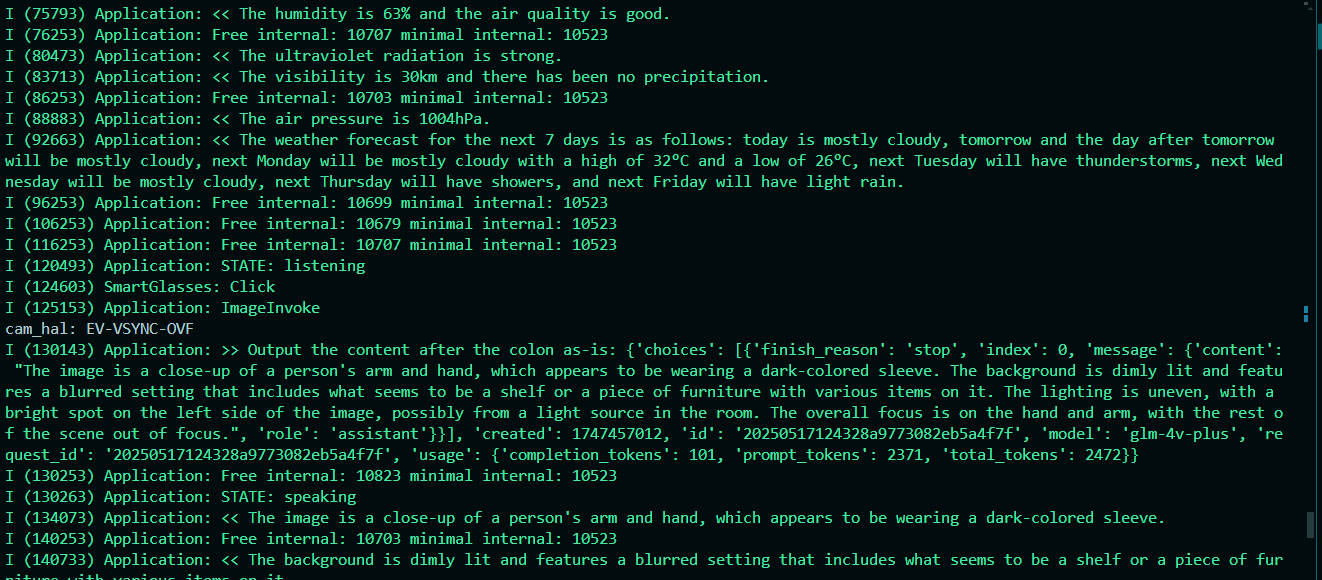
- Image Recognition Function
3.3 Repository Links
- [xiaozhi-esp32] https://github.com/lynnl4/xiaozhi-esp32
- [xiaozhi-esp32-server]https://github.com/lynnl4/xiaozhi-esp32-server