Week17 - Wildcard Week
The task of the assignment
- Design and produce something with a digital process (incorporating computer-aided design and manufacturing) not covered in another assignment, documenting the requirements that your assignment meets, and including everything necessary to reproduce it.
Computer Vision
Computer vision is a field of artificial intelligence (AI) that uses machine learning and neural networks to teach computers and systems to derive meaningful information from digital images, videos and other visual inputs—and to make recommendations or take actions when they see defects or issues.
Computer vision needs lots of data. It runs analyses of data over and over until it discerns distinctions and ultimately recognize images. For example, to train a computer to recognize automobile tires, it needs to be fed vast quantities of tire images and tire-related items to learn the differences and recognize a tire, especially one with no defects.
Two essential technologies are used to accomplish this: a type of machine learning called deep learning and a convolutional neural network (CNN).
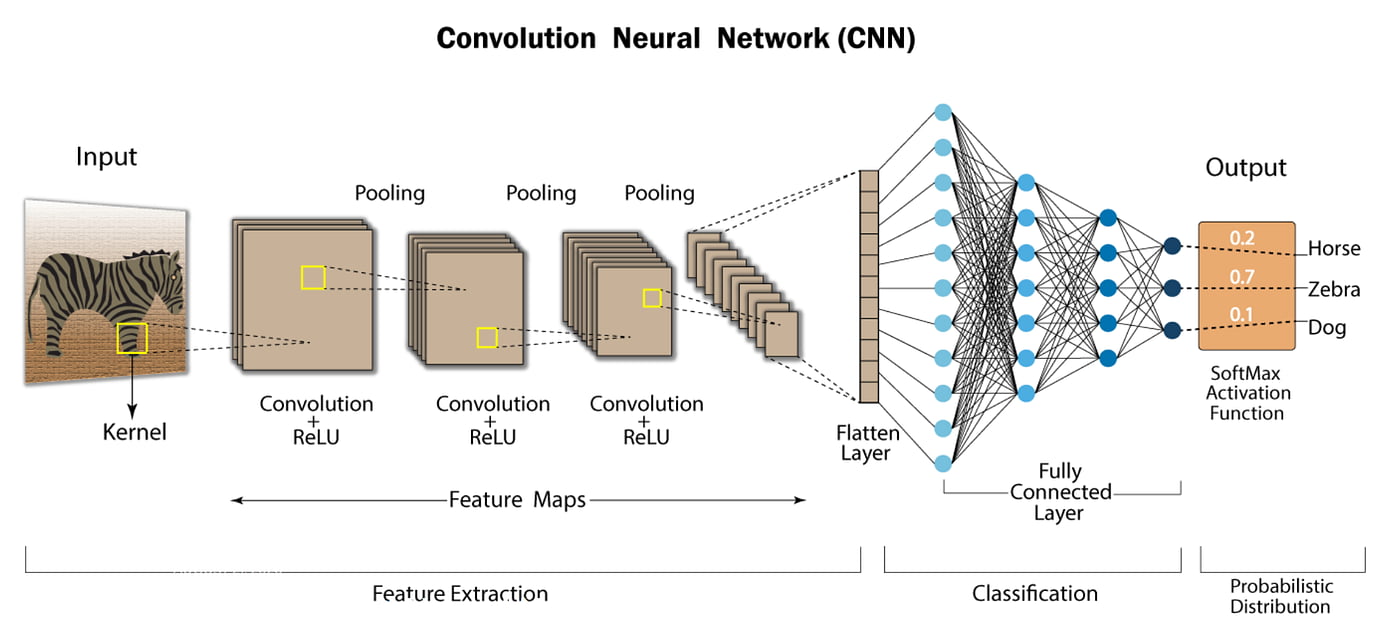
Machine learning uses algorithmic models that enable a computer to teach itself about the context of visual data. If enough data is fed through the model, the computer will “look” at the data and teach itself to tell one image from another. Algorithms enable the machine to learn by itself, rather than someone programming it to recognize an image.
A CNN helps a machine learning or deep learning model “look” by breaking images down into pixels that are given tags or labels. It uses the labels to perform convolutions (a mathematical operation on two functions to produce a third function) and makes predictions about what it is “seeing.” The neural network runs convolutions and checks the accuracy of its predictions in a series of iterations until the predictions start to come true. It is then recognizing or seeing images in a way similar to humans.
Much like a human making out an image at a distance, a CNN first discerns hard edges and simple shapes, then fills in information as it runs iterations of its predictions. A CNN is used to understand single images. A recurrent neural network (RNN) is used in a similar way for video applications to help computers understand how pictures in a series of frames are related to one another.
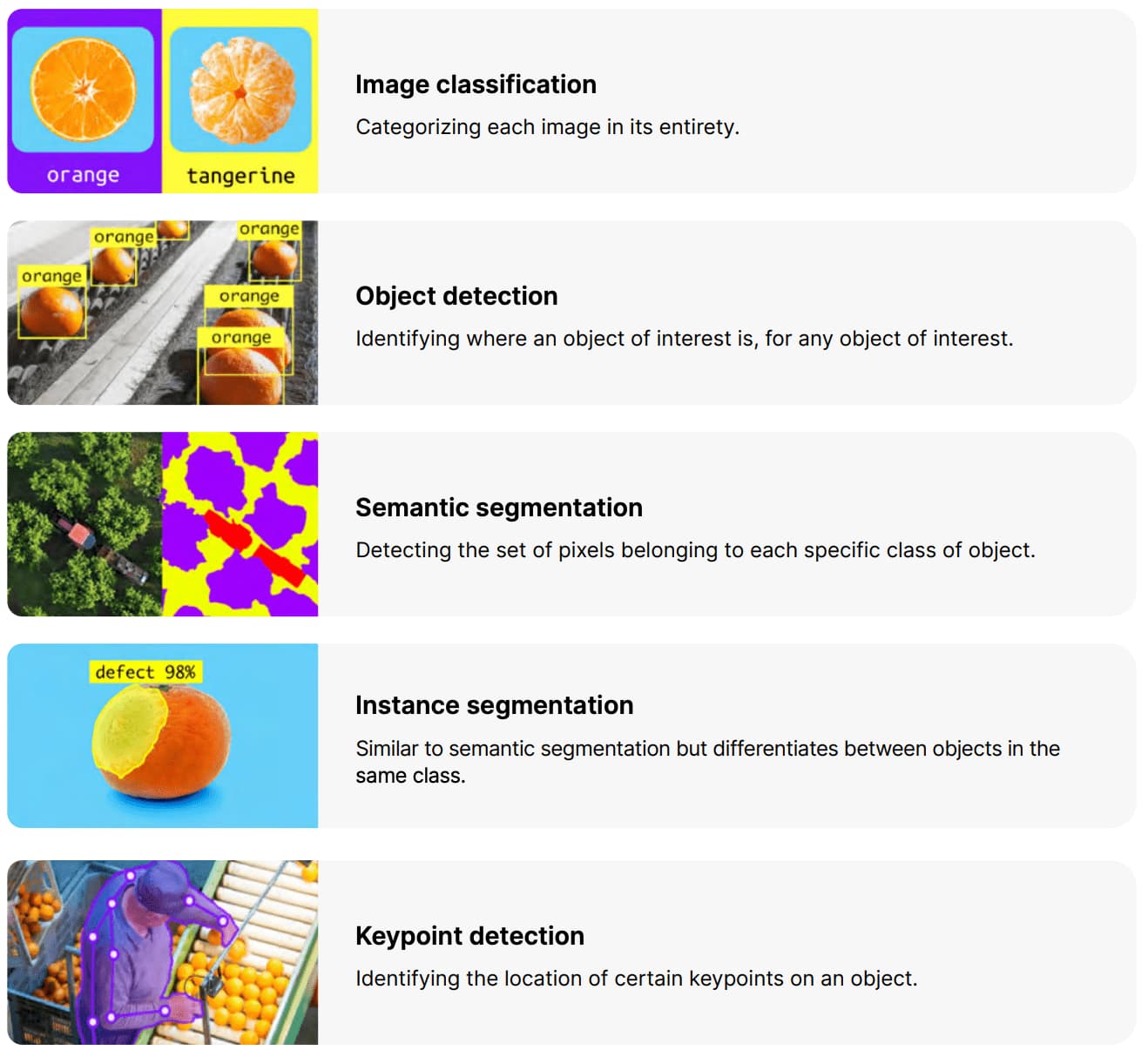
Tasks of computer vision
-
Image classification sees an image and can classify it (a dog, an apple, a person’s face). More precisely, it is able to accurately predict that a given image belongs to a certain class. For example, a social media company might want to use it to automatically identify and segregate objectionable images uploaded by users.
-
Object detection can use image classification to identify a certain class of image and then detect and tabulate their appearance in an image or video. Examples include detecting damages on an assembly line or identifying machinery that requires maintenance.
-
Object tracking follows or tracks an object once it is detected. This task is often executed with images captured in sequence or real-time video feeds. Autonomous vehicles, for example, need to not only classify and detect objects such as pedestrians, other cars and road infrastructure, they need to track them in motion to avoid collisions and obey traffic laws.
-
Content-based image retrieval uses computer vision to browse, search and retrieve images from large data stores, based on the content of the images rather than metadata tags associated with them. This task can incorporate automatic image annotation that replaces manual image tagging. These tasks can be used for digital asset management systems and can increase the accuracy of search and retrieval.
Overview of Yolo11
YOLOv11 is a series of computer vision models developed by Ultralytics. As of the launch of YOLOv11, the model is the most accurate of all Ultralytics’ models.
YOLOv11 introduces the C3k2 (Cross Stage Partial with kernel size 2) block, SPPF (Spatial Pyramid Pooling - Fast), and C2PSA (Convolutional block with Parallel Spatial Attention) components. These new techniques advance feature extraction and improve model accuracy which continues the YOLO lineage of better models for real-time object detection use cases.
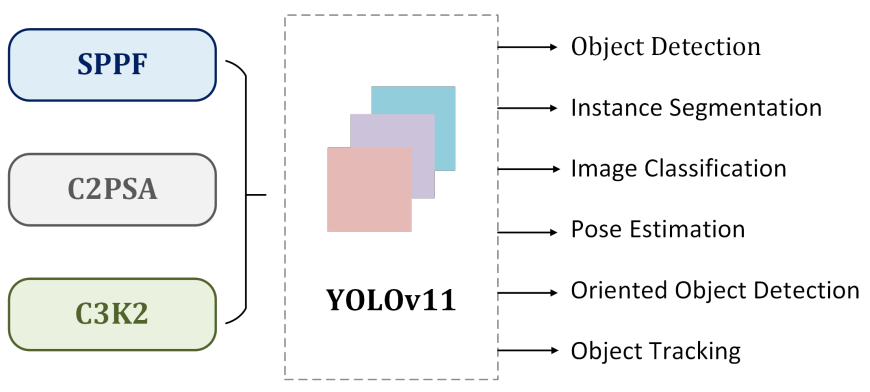
The C3k2 block replaces the C2f block in previous YOLO models which is more computationally efficient and improves processing speed.
YOLOv11 supports multiple task types including object detection, classification, image segmentation, keypoint detection, and Oriented Bounding Box (OBB).
Install Yolo11
In windows, there's a open source library should be installed -- Ultralytics.
Open a terminal and input the following commands to install ultralytics.
pip install ultralytics
There are two important libraries needed to be installed.
PyTorch is a machine learning library based on the Torch library, used for applications such as computer vision and natural language processing, originally developed by Meta AI and now part of the Linux Foundation umbrella.
CUDA (Compute Unified Device Architecture) is a proprietary parallel computing platform and application programming interface (API) that allows software to use certain types of graphics processing units (GPUs) for accelerated general-purpose processing, an approach called general-purpose computing on GPUs.
CUDA 12.8 can be downloaded here.
After installing CUDA, install pytorch with the following setting.

CUDA will be linked with Pytorch. I choose CUDA12.8 version.
Input the following command to install Pytorch with CUDA.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
Checking installation of ultralytics
First, I check the installation of Pytorch with the following code
import torch
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.version.cuda)
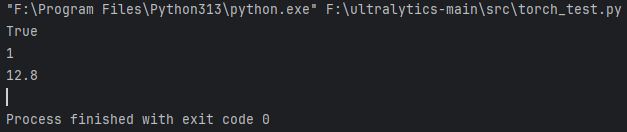
The information is shown that the CUDA is available in my computer, 1 device can be activated with CUDA and CUDA v12.8 is applied.
Then, use the following code to check the installation of ultralytics.
import ultralytics
ultralytics.checks()

The results are shown that Ultralytics 8.3.141 is installed and Pytorch v2.7.0 with CUDA is available.
YOLO11 is ready.
Testing function of Yolo11
In this part, I test Yolo11 with the following code.
from ultralytics import YOLO
from huggingface_hub import hf_hub_download
import cv2
import matplotlib.pyplot as plt
# Load a Model
model = YOLO("yolo11n.pt")
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image from internet
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
A official model yolo11n.pt file will be downloaded when the code is running.
In result variable, a picture is captured (in this case, the image is captured from internet) and input to the yolo11 model.

The predicting result will be saved in result variable and shown on matplotlib windows.

There are 4 persons detected and 1 bus is detected in bus.jpg and marked into rectangular boxes.
Then, I use the other official model yolo11n-seg.pt to test Yolo11.
from ultralytics import YOLO
import matplotlib.pyplot as plt
# Load a model
model = YOLO("yolo11n-seg.pt") # load an official model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image from internet
# Access the results
for result in results:
xy = result.masks.xy # mask in polygon format
xyn = result.masks.xyn # normalized
masks = result.masks.data # mask in matrix format (num_objects x H x W)
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()

In yolo11n-seg.pt model, there's a function - object segmentation which is used for marking the objects in the image due to its appearance.
I also find other images about cats from internet.

Running the code and get the result:

2 cats and 1 bed are recognized.
Dataset Training
Yolo11 can also used for training dataset for recogizing specific items.
Here's the basic training code:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
if __name__ == '__main__':
# Train the model on the COCO8 example dataset for 10 epochs
results = model.train(data="coco8.yaml",epochs=10, imgsz=640)
Based on a pretrained model - yolo11n.pt, a extra database coco8 which can be used for recogizing about 80 different items.
In my coding, 10 epochs mean train the data by 10 times.
Here's the process of training:
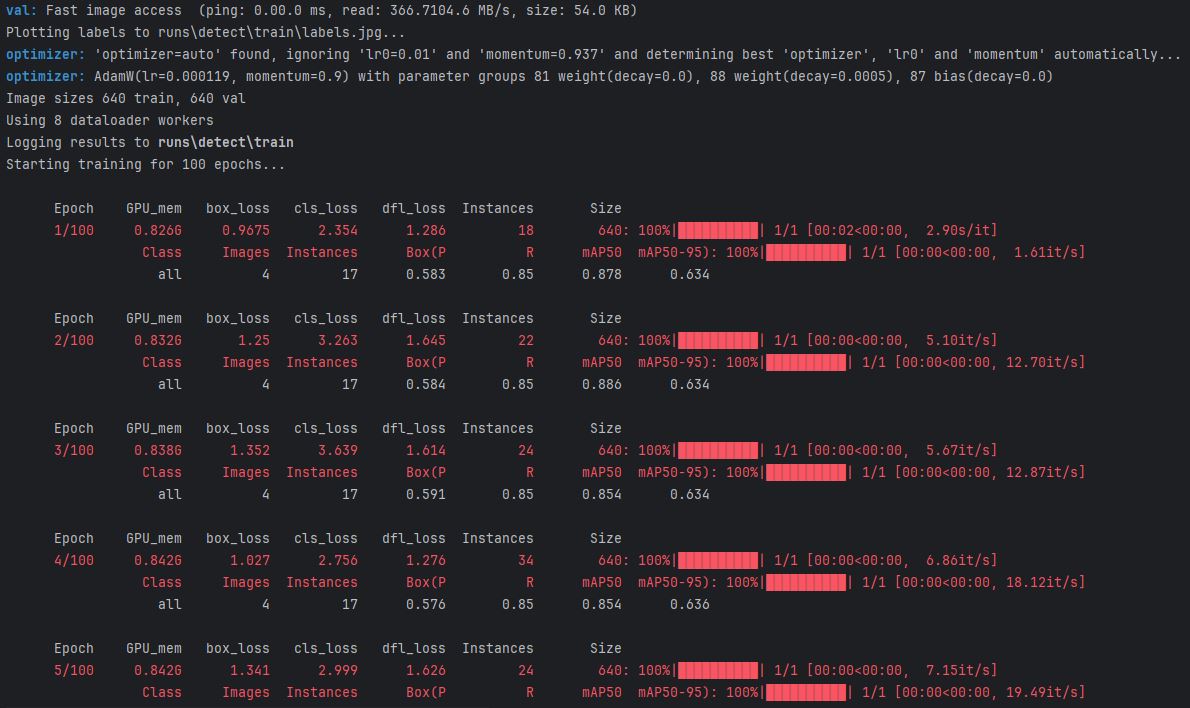
After training, a weight file is generated at
run/detect/train/weights/best.pt
Then, change the code as following:
from ultralytics import YOLO
from huggingface_hub import hf_hub_download
import cv2
import matplotlib.pyplot as plt
# Load a Model
model = YOLO("runs/detect/train/weights/best.pt")
# Predict with the model
results = model("https://wpcdn.web.wsu.edu/cahnrs/uploads/sites/4/cat2-1024x676.jpg")
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
where the file name is modified in model variable.

It's a cat photo and 1 cat, 1 potted plant are detected.
Open Dataset Training
The open dataset can be used for training custom model for recognizing the specific item.
Roboflow provides lots of open models. It's suitable for Yolo11.
For example, a dataset Aquarium which is used for recognizing sea animals. This dataset consists of 638 images collected by Roboflow from two aquariums in the United States: The Henry Doorly Zoo in Omaha (October 16, 2020) and the National Aquarium in Baltimore (November 14, 2020). The images were labeled for object detection by the Roboflow team.
The dataset can be downloaded by the following steps:
Click 'Download', and choose version 'YOLOv11'.
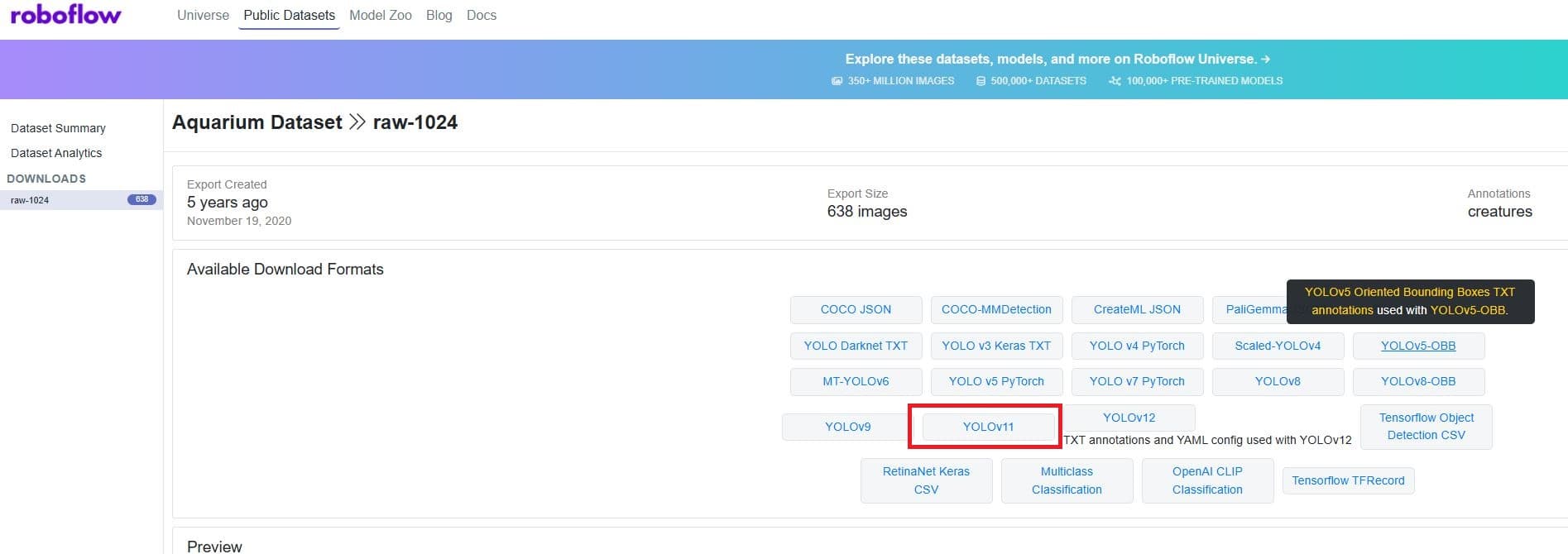
Choose the format 'YOLOv11' and choose the option 'Download zip to computer'. Click 'Continue' to start the download.
Extract the dataset in your python project.
In a dataset with Yolo11 format, there's the standard format.
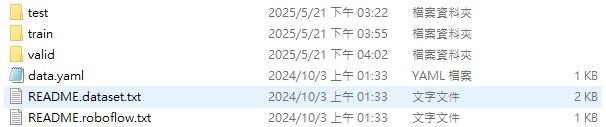
- 3 types of data: testing data, training data and valid data for training
- data.yaml for recording the link of the training data
There are 7 classes in this dataset.
- Fish
- JellyFish
- Penguin
- Shark
- Puffin
- Stingray
- Starfish
I tried to input the video stream from youtube to python as the following code. Explaination will be inserted into the code.
from ultralytics import YOLO
import cv2
from datetime import timedelta
from cap_from_youtube import cap_from_youtube
# Load a Model
model = YOLO("datasets/aquarium/runs/detect/train/weights/best.pt") #load the trained model
# Predict with the model from youtube video stream
youbube_url = 'https://www.youtube.com/watch?v=LYC4SDnw3cA'
start_time = timedelta(seconds=0)
cap = cap_from_youtube(youbube_url, 'best', start=start_time) #input the video stream into cap variables instead of cap = cv2.VideoCapture
# Visualize predictions
fps = int(cap.get(cv2.CAP_PROP_FPS)) #get fps from source video
fourcc = cv2.VideoWriter_fourcc(*'mp4v') #mp4 encoder
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # get the width of source video
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # get the height of source video
output_path = "output_video.mp4" #output file name
out = cv2.VideoWriter(output_path, fourcc, fps,(frame_width, frame_height)) #Input the parameters into cv2.VideoWriter
#Process video frames
while True:
ret, frame = cap.read()
if not ret:
break
#Run estimation with tracking enabled
results = model.track(frame)
#Visualize the tracked on the frame
result_frame = results[0].plot()
#Write the frame to output video
out.write(result_frame)
#Release resources
cap.release()
out.release()
print(f"Estimation video saved as {output_path}")
Here's the source video from youtube.
There is output video which included the recognized result.
Online Tracking (Webcam)
Same as the video stream capture, online tracking is possible to achieved. Modify the code as below(The explainsion also shown in the code):
from ultralytics import YOLO
import cv2
# Load a trained Model
model = YOLO("runs/detect/train/weights/best.pt")
# Initial the camera
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
#Process video frames
while True:
ret, frame = cap.read()
if not ret:
break
#Run prediction with tracking enabled
results = model.track(frame)
#Visualize the tracked on the frame
result_frame = results[0].plot()
#Write the frame and display by cv2.imshow
cv2.imshow('frame', result_frame)
if cv2.waitKey(1) == ord('q'):
break
#Release resources
cap.release()
cv2.destroyAllWindows()
In the model variable, the coco8.pt pretrained model is loaded to this test code.
Finally, the online object recognation function is achieved!!
![]()
The cell phone and I can be recognized successfully! The picture on my phone case can be recogize as person correctly. If some specific target want to be recognized, download the corresponding dataset and train it, then call the weights file to start the recognition program.