Wildcard Week
Here its our group assigment: Week 15For this week...
Teachable Machine, developed by Google's Creative Lab, is a user-friendly web-based tool that simplifies the process of creating machine learning models without the need for coding expertise. It enables users to train models using their webcam or uploaded data, such as images, sounds, or poses. Users define categories and provide examples for each to train the model. Once trained, the model can classify new input data into these categories in real-time. Teachable Machine offers customization options for experimenting with model settings, and it can be used for various applications like image classification, sound recognition, and pose detection.
Teachable Machine offers customization options for experimenting with model settings, and it can be used for various applications like image classification, sound recognition, and pose detection.
Image project:
Image classification in Teachable Machine operates by training a machine learning model to differentiate and categorize various classes or categories of images based on the supplied training examples. Users begin by collecting a dataset comprising images representing different classes they aim to recognize with the model. For instance, if developing a model to identify fruits, the dataset might encompass images of apples, bananas, oranges, and so forth. Once the dataset is compiled, it undergoes preprocessing and segmentation into training, validation, and testing sets. Subsequently, Teachable Machine employs a pre-built convolutional neural network (CNN) architecture, such as MobileNet, for model training. Throughout the training process, the model learns to discern patterns and features within the images that distinguish one class from another. Adjustments to the model's parameters occur iteratively using optimization algorithms like stochastic gradient descent (SGD) to minimize prediction errors.

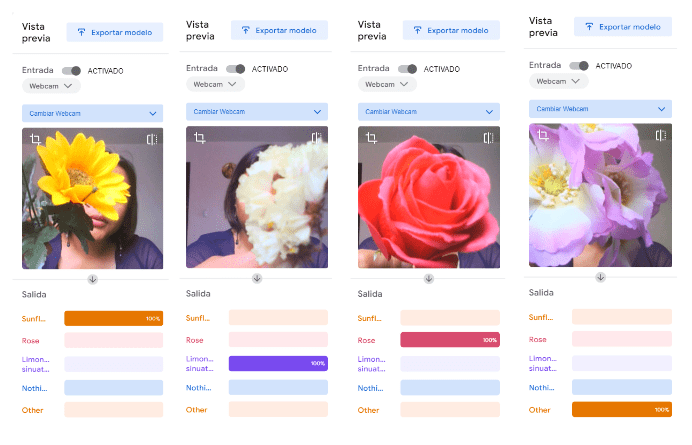
The initial step in the image classification process involves gathering data, which in this case entails uploading images. I collected approximately 600 images to ensure a larger dataset for increased precision. Following data collection, the next stage involves image processing, where the uploaded images undergo various preprocessing techniques such as resizing, normalization, and augmentation to prepare them for training. Subsequently, the third step entails obtaining the classification results. Once the model is trained on the processed images, it can accurately classify new, unseen images into predefined categories based on the patterns and features learned during training. Thus, the sequential progression from data collection to image processing to result acquisition constitutes the fundamental framework for image classification tasks in this context.

Result
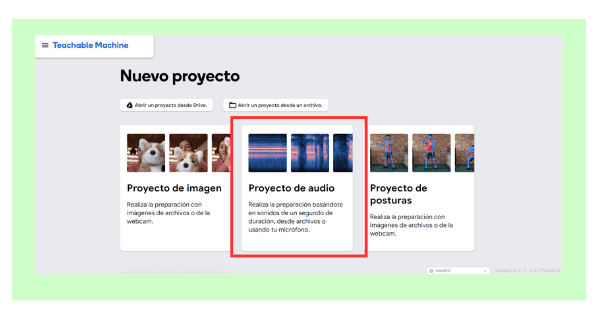
Voice project:
Teachable Machine operates by leveraging machine learning algorithms to analyze and classify audio data, enabling users to train models without extensive coding knowledge. Users begin by providing a dataset comprising audio samples representing different categories or classes they aim to recognize. For instance, if developing a model to identify musical instruments, the dataset might encompass audio clips of guitars, pianos, drums, and so forth. Teachable Machine employs a pre-built neural network architecture, such as a convolutional neural network (CNN) or recurrent neural network (RNN), to process the audio data and extract relevant features. During training, the model learns to differentiate between the audio classes by identifying unique patterns and characteristics within the sound waves. Adjustments to the model's parameters occur iteratively through optimization algorithms like gradient descent to minimize prediction errors and improve accuracy. Once trained, the model can classify new, unseen audio samples into the predefined categories based on the learned patterns.
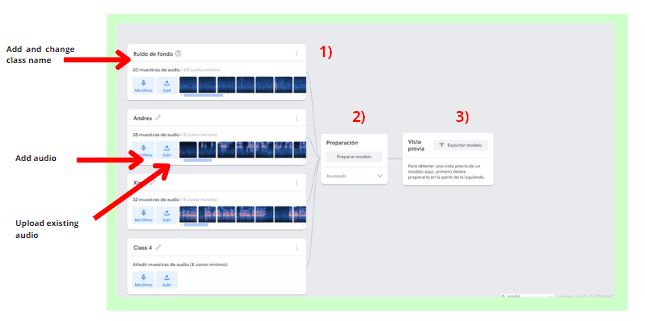
During my practice session, I encountered a situation where I didn't have anyone else at home to help me with recording audio samples. As a solution, I enlisted the help of my boyfriend via a phone call to record audio snippets for me to use. Additionally, I thought it would be amusing to use the voice of Neil from the Zoom call recordings for this purpose. Surprisingly, this unconventional approach proved to be somewhat effective, demonstrating the flexibility and adaptability of Teachable Machine in accommodating different input sources. Despite the unconventional nature of the setup, it allowed me to proceed with my practice and achieve some degree of success in training the audio classification model.
Result
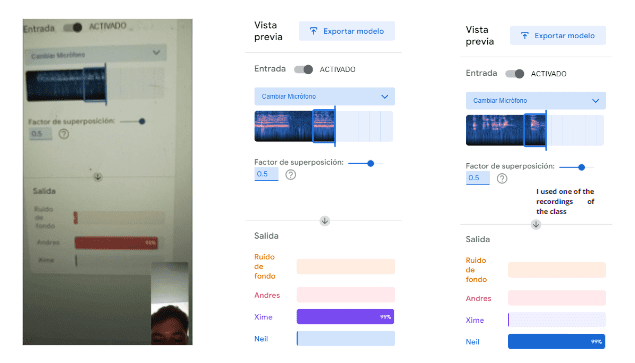
It won't let me put it, but here is the link if you are Andres, Xime or Neil :0
Link: https://teachablemachine.withgoogle.com/models/oaYA2BtGr/Postures project:
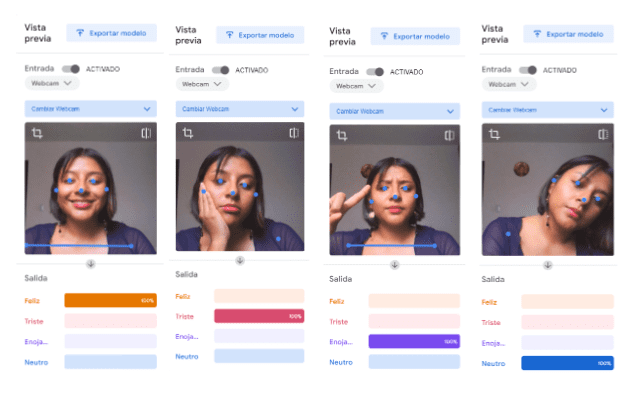
Teachable Machine for pose detection operates through the utilization of machine learning algorithms, primarily based on convolutional neural networks (CNNs) or pose estimation models like PoseNet. The process begins with data collection, where users compile a dataset comprising images or videos showcasing various human body poses they aim to recognize. This dataset encompasses examples of poses from diverse angles and perspectives to ensure comprehensive training. Subsequently, the model undergoes training, during which it learns to identify key points on the human body, such as joints and limbs, and their spatial relationships in different poses. Optimization algorithms iteratively adjust the model's parameters to minimize errors and enhance accuracy.

Result
It won't let me put it, but here is the link if you want to try it:
Link: https://teachablemachine.withgoogle.com/models/_FLOLtw1l/Mistakes and how I solve them
| Problem | How we solve it | One of the challenges I encountered was that initially, with a smaller dataset of around 100 photos, the model tended to misinterpret certain poses more frequently. This led to inaccurate predictions and reduced performance. | To address this issue, I increased the size of the dataset by collecting more photos. By expanding the dataset, the model had a larger variety of examples to learn from, resulting in improved accuracy and better generalization to different poses. |
|---|